Multi-Computing PC Card PC Card - Part 2

Prezentacja dotyczy:
- studneckiego możliwie nisko-budżetowego rozwiązania,
- karty wielofunkcyjnej PCI lub działającej samodzielnie,
- opartej o sprawdzone [starsze] układy scalone,
- oraz darmowe środowiska programistyczne do budowy software [C/C++] oraz firmware [HDL].
W ninniejszej części zostanie przedstawiony tok tworzenia architektury karty wraz z najważniejszymi połączeniami układów elektronicznych.

W prezentacji zostanie przedstawione:
- krótkie nawiązanie do części poprzedniej prezentacji,
- główne rozważania dzięki którym uzyskano architekturę,
- uwarunkowanie wyboru FPGA,
- przedstawienie właściwej architektury,
- wytyczenie działań na następny rok.
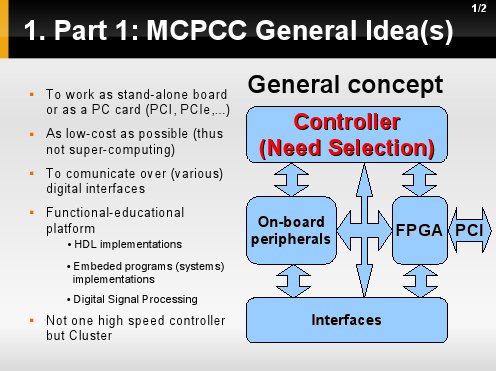
Generalnie MCPCC jest kartą samodzielną lub kartą PCI stanowiącą platformę dla:
- cyfrowego przertwarzania - głownie Video,
- systemów wbudowanych,
- systemów wieloprocesorowych,
- rozwojową HDL, C\C++, a w tym zw. z ESL gdzie FPGA stanowi koprocesor.
Na rysunku widzimy podstawową koncpecję, gdzie dostep do peryferiów oraz interfejsów płyty jest współdzielony przez kontroler wraz z układem FPGA - co ma umozliwać stworzenie połączeń typu sieciowego. Sprawdzone zostanie m.in. wydajność rozwiązania sprzętowego, gdzie FPGA stanowi koprocesor do działań nad strumieniem Video.
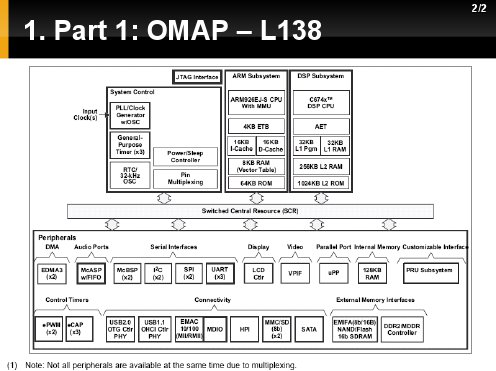
W poprzedniej prezentacji wybrany został hybrydowy kontroler uP+DSP L138. Jego zaletami poza wysokim współczynniem wydajności do ceny są zaimplementowane sprzętowo interfesjy na bazie których można stworzyć w pełni funkcjonalny "mini-komputer" tzw. "single board computer" lub kartę przetważania Video [jedno nie wyklucza drugiego]. Ponadto układ ten posiada dwa dedykowane interfesjsy do połączeń wieloprocesorowych:
- Host Port Interface [HPI]- dający mozliwość połączenia typu szeregowego wraz innym układem mającym taki interfejs,
- Universal Parallel Port [UPP] - dający mozliwość połączenia typu magistrali wraz z innymi układami niekoniecznie mającymi taki sam interfesj, gdyż protokół UPP jest kompatybilny z wieolma innymi np. z WishBone.

Architektura tworzona jest z myślą o jak najlepszym wykorzsytaniu interfesjów L138 i stworzenia optymalnych połączeń nieograniczjących funkcjonalności rozwiązania.
Głównymi przemyśleniami są: w jaki sposób połączyć dane interfesjy naszego uP tak aby stworzyć jak najwydajniejszy system wieloprocesorowy i zarazem zrobić to najmniejszymu kosztami. W przypadku gdy tworzymy system wiloprocesorowy [z zachowaniem umiaru w kosztach], to najmniejszym takim sytemem będzie system dwu-procesorowy [w zasadzie jest on cztero-procesorowy gdyż na pokładzie L138 znajduję się dodatkowo rdzeń DSP]. Jako, że nie jestesmy w stanie w pełni przewidzieć czy dana archotektura jest najlepsza, to warto pierw opracować prototyp tylko z dwoma uP by nie popaść w nic nieprzynoszące koszta i zweryfikować skalowalność rozwiązania.
Na obrazku widzimy, iż pierwszą ideą tworzącą naszą architekturę jest wykorzystanie 2 uP, gdzie wykorzystamy interfesj HPI jako połączenie bezpośrenide.
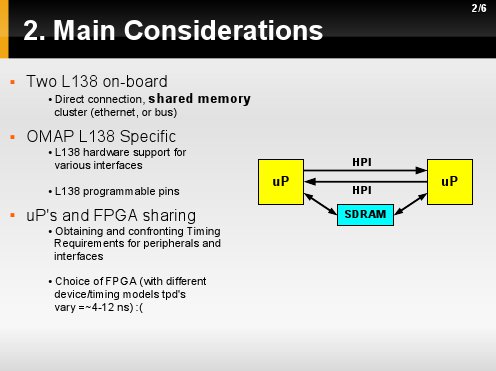
Mając już dwa uP możemy pomysleć nad innymi mozliwościami połączeń takimi jak współdzielona pamięć. Takie połączenie może stanowić kolejny mechanizm w wymianie informacji pomiędzy procesorami w systemi wieloporcesorowym.
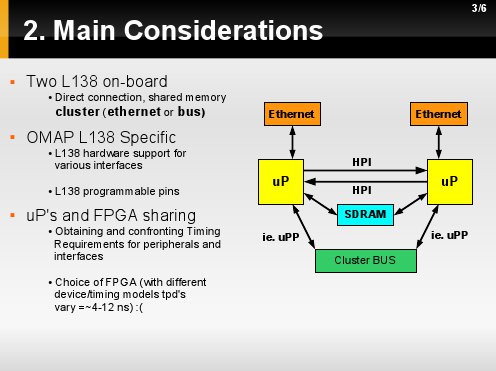
Kolejnymi pomysłami jest stowrzenie magistrali oraz możliwości połączenia przez Ethernet.
Nasza architektura tworzona jest tak by wykorzystać wszystkie mozliwości jakie daje L138 do stworzenia systemu wieloprocesorowego tak aby projektant oprogramowania mógł wykorzystać najwydajnieszy sposób połacznia dla zadanego [swojego] algorytmu/zadania.
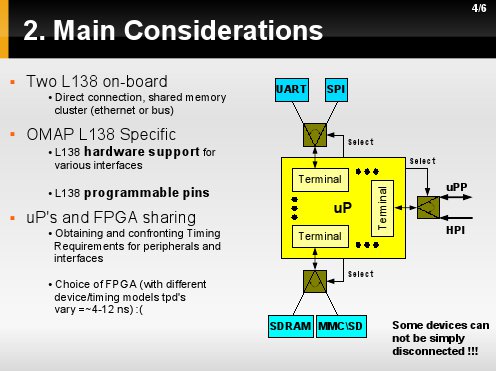
L138 posida sprzętowe wsparcie dla wielu interfejsów ciekawych z punktu widzenia platformy rozwojowej. Niestety nie są one dostepne wszystkie naraz - są one komutowane i mogą być komutowane podczas działania online. Niestety niktóre interfejsy [w zalezności do czego i jak są podłączone] nie mogą być współdzielone np. UART z I2C. Nie mogą przeto być komutowane a muszą być wybrane na stałe. Ponadto na róznych interfejsach które nawet dałoby się podłączyć równolegle podczas komutacji może dojć do nieprzewidywanych zachowań.
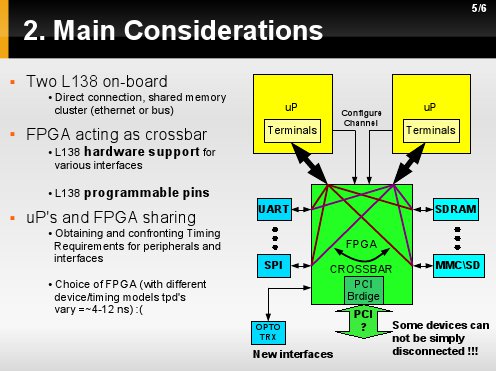
Stąd pomysł na podłączenie jak największej ilośći pinów uP do FPGA, które w prostym ujęciu stanowi powielacz pinów, a wew. FPGA może zachodzić "inteligętna" komutacja.
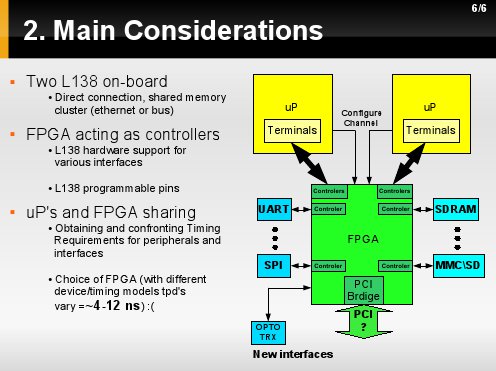
Lub nawet zamiast tylko komutacji przejęcie sterowania na dowolnym interfesjem poprzez stowrzenie kontrolerów/arbitrów - otrzymujących sterowanie/dane z uP lub pełniące funkcję DMA.

By propopnowane rozwiązanie uzykało pełny potencjał, tj. każdy interfesj L138 mógłbyć fizycznie dostepny, należałoby użyć FPGA o ponad 740 funkcjonalnych pinach. Takie FPGA są poza zakresem obsługiwanych w darmowych wersjach środowisk do tworzenia firmware dla FPGA [na rok 2011]. By sprostac wymaganiowi na niskie koszta zostało ustalone, iż nie wszystkie możliwości L138 zostaną zaimplementowane. Prowadzi to do zrezygnowania z wielu połączeń, które miały pierwotnie przechodzić przez FPGA.

Do projektu zostanie wykorzystany największy pod względem ilości dostęnych IO oraz jednocześnie wspierany przez darmowe wersje oprgoramaowania [na rok 2011] do tworzenia firmware - Cyclone II. Główe parametry widoczne są na rysunku.
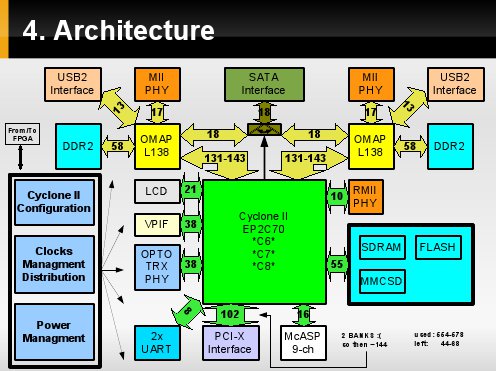
Tak prezentuję się architektura. Przez FPGA zostaną przepuszczone [współdzielone] interfejsy:
- VideoIn,
- VideOut - LCD,
- Audio,
- pamięć FLASH [bootowanie L138 poprzez FPGA],
- UPP oraz HPI,
- interfesjs do zew. PHY [SerDes'a] optycznej transmisji danych.
Dedykowanymi dla danego uP będzie połączenie z:
- PHY ethernetowym interfesjem MII,
- DDR2,
- USB,
- komutowanym kontrolerem SATA podłączonym do zew. dysku.

Po opracowaniu architektury [co wymagało zweryfikowania fubkcjonalności L138 wraz z wybranym FPGA], można przejść do opracowywania PCB oraz fimrware na FPGA. Jako, że wiele interfejsów jest "przepuszczona" przez FPGA, a interfesjy te mają wymagania/rygory czasowe w których transmisja musi się mieścić, to należy pierw opracować firmware by uzyskać opóxnienia czasowe zw. z architekturą wew. FPGA. Opóźnienia te należy wziąść pod uwagę razem z opóźnieniami ścieżek zasymulowanych w oprogramowaniu tj. HyperLynx lub Altium Desinger.

| Attachment | Wielkość |
|---|---|
| Multi-Computing PC Card PC Card - Part 2.pdf | 178.51 KB |