Prezentacje
Zbiór naszych prezentacji
FPGA Mezzanine Card DSP Module

We would like to present an outline of our project which is ”FPGA Mezzanine Card DSP Module”.

Plan of our presentation consists of:
- Short introduction to what this card is being made for,
- A glance into the FMC standard,
- Sterssing out main assumptions and general solution scheme,
- Short characteristic of chosen DSP and FPGA,
- Presenting the architecture we came up with,
- And finnaly pointing out ”Done and To Do list”.

Origin of our project comes from the JET experiment, which is a plasma physics experiment, that from our point of view, produces huge ammount of data to be processed.
JET is equipped with many diagnostics systems some of which are pointed out here.
Data mining system has been proposed that is scalable using FPGA Mezzanine Card Standard.
Our project is to be used as a part of this data mining system. Namely to boost up the X-ray spectrometer calculations by using the DSP FMC accelerator module.

A quick overview of the FMC standard
This standard defines two shapes of FMC plugin module, single width, and double width. We focus on single width module. An example is shown on the picture here. The idea is very simple like in other Mezzanine cards -- to add functionality to the carrier cards by pluging in the FMC module.
For the plug-in purposes, FMC standard specifies Samtec’s SEARAY™ connector set.
Standard also defines two pinout versions for this connector
Low–Pin count and High–Pin count.
Low-pin count comes with 160 pins. High-pin count comes with 400 pins.
The main differences are pointed out here on the page
Low–Pin count is a subset of high–pin count
and is mechanically compatible with High–Pin connector.
The pinout consist mainly of dedicated:
- clock pins,
- JTAG pins,
- I2C pins,
- power pins,
- transciever pins,
- and user defined signal pairs.
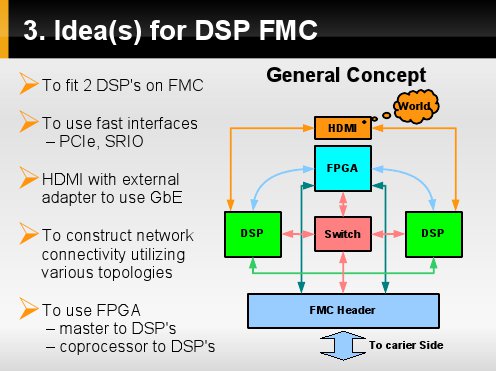
To fulfill the aim of the project we came up with some basic assumptions:
- first, to fit 2 DSP's on our module, it's not many but still they make a cluster,
- second, to use fast and digital only interfaces,
- third, to construct different types of connectivity, allowing to chose one that suits a particular algorithn the best,
- and the last one, to use FPGA which could be working as: a master to DSP's or as coprocessor to DSP's.
General solution scheme is shown here on a picture. We can see two processors – connected via point to point link, by a switch, by FPGA and possibly by ethernet.
FPGA and the switch in the end, are connected to the FMC header for exchanging data with the carier board.
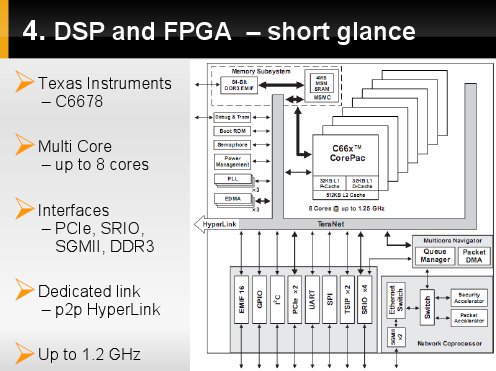
To realize our basic solution scheme many different DSP's and FPGA's can be used.
In place of DSP we had chosen, possibly today's fastest, TMS C66 78 from Texas Instruments.
DSP's insides are shown on the picture here.
This DSP has fast interfaces like:
- PCI expess,
- SGM double I allowing for gigabit ehternet,
- Serial Rapid-IO,
- dedicated point-to-point link,
Computing power of all 8-cores is calculated to be 160 GFLOPs

In place of FPGA we had chosen Spartan-6 from Xilinx.
FPGA was chosen to be possibly the smallest and yet having possiblity to connect it to fast interfaces like PCI express, Serial RApid-IO and DDR 3 interface.
Above to that, FPGA comes handy to utlize free IOs as FMC's user-defined singals – that is where 190 IO's are useful
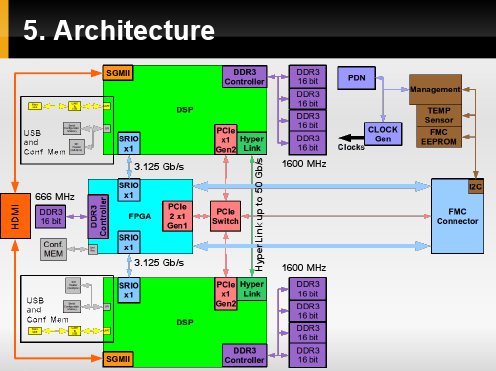
Architecture we came up with is shown on the picture, additionally possible transfer speeds are also shown.
In few words:
- the managment block controls and suprevises power network and clock distribution,
- when FPGA is powered up and programmed using FLASH or JTAG -- it configures DSPs for bootloading via for instance FLASH , ethernet or PCI express,
- additonally to all the fast interfaces, there is also UARTs translated to USB for debugging purposes,
- the central point of this board is the PCI express switch that uses packet header information for how and where to pass the data -- it is called a non-blocking switch,
- every unit capable of processing is equipped with RAM memories allowing for wider spectrum of algorithms to be implemented,
- in the the end, we can see a mesh network-like connectivity.

This is the first semester of this project and schematics are almost complete. We aim to design schematics before the end of February.
This might need some redesigning in the future however, becuse chosen DSP still has an experimental staus
3 last steps lies ahead of us:
- programing FPGA, which might catch critical errors, so that we could redisgn the schemtacis before completing PCB layout,
- offcourse to do PCB layout, which might be hard due to fast interfaces and lack of producent provided FPGA and DSP PCB libraries,
- and final step to program and test the borad.

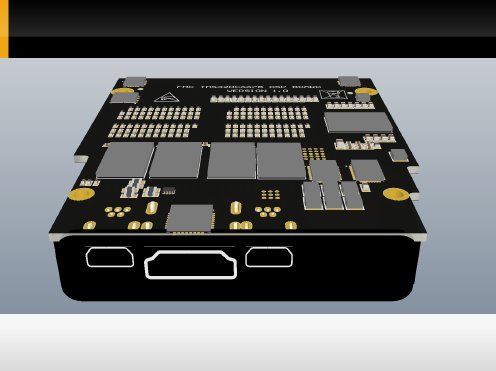
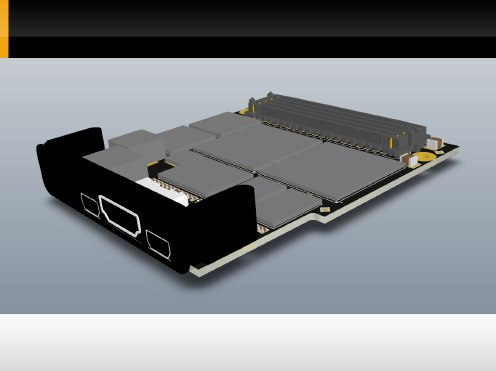
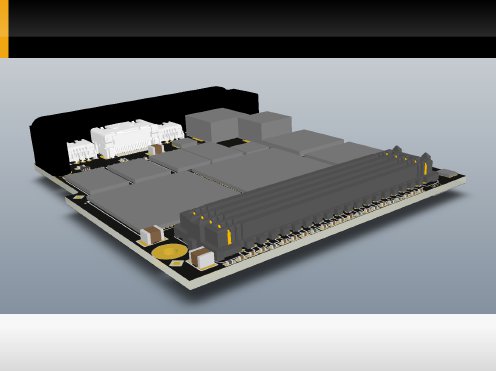
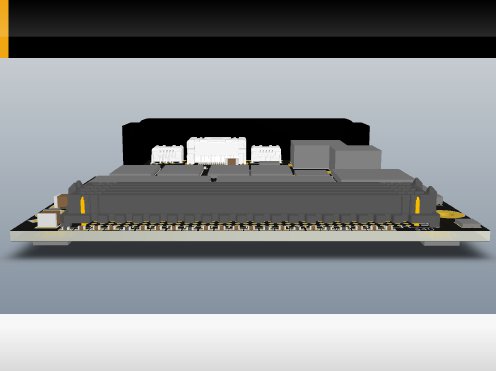
This is a 3D model of the propsoed PCB from diffretent POVs.

| Attachment | Wielkość |
|---|---|
| FPGA Mezzanine Card DSP Module [2011].pdf | 4.17 MB |
Mobile Measurement System





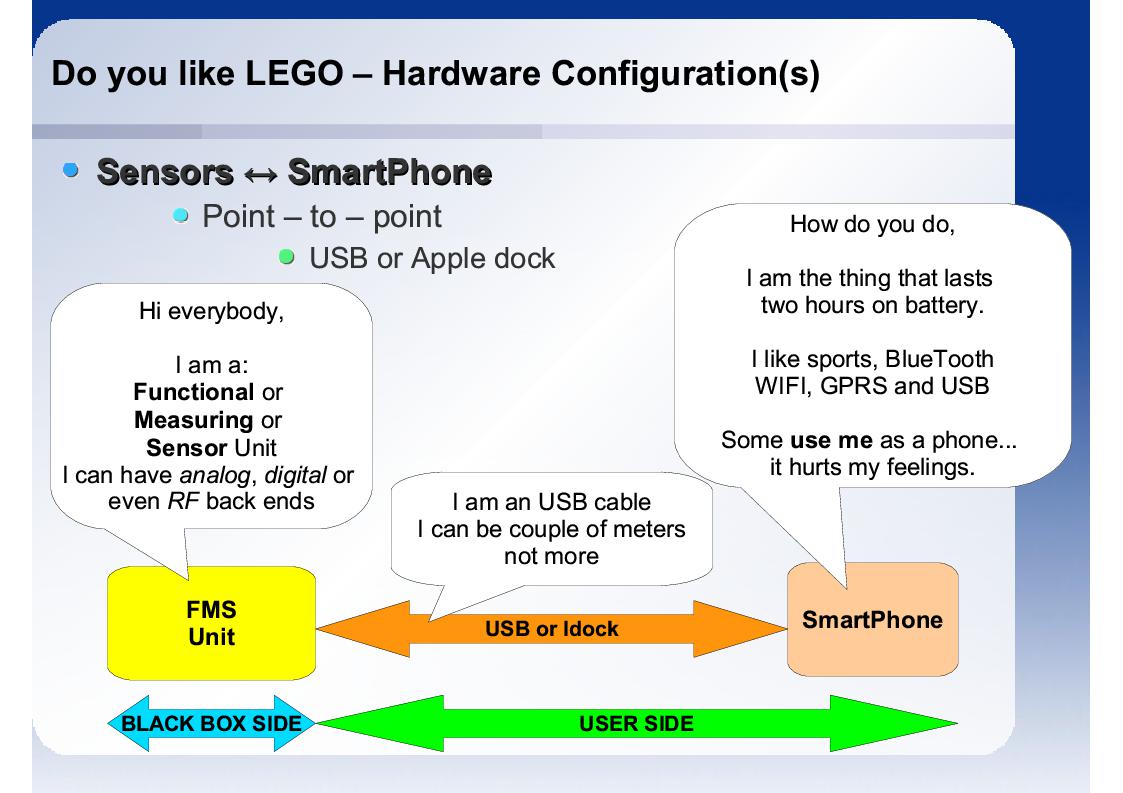
Konfiguracja sprzętowa zalezna jest od połączenia jednostek w MMS. Smartfony typowo wyposażone są w interfesj USB [lub IDOCK w przypadku Apple], który jest połączeniem szeregowym. W takiej konfiguracji uzytkownik musiałby podłączać się do każdego urządzenia z osobna, co prowadzi do zbyt licznej fizycznej ingerencji przez użytkownika w system połączeń. W założeniu MMS ma być widziany przez użytkownika jako "czarna skrzynka". W takiej konfiguracj zbyt mało całego MMS mieści się ów "czarnej skrzynce".
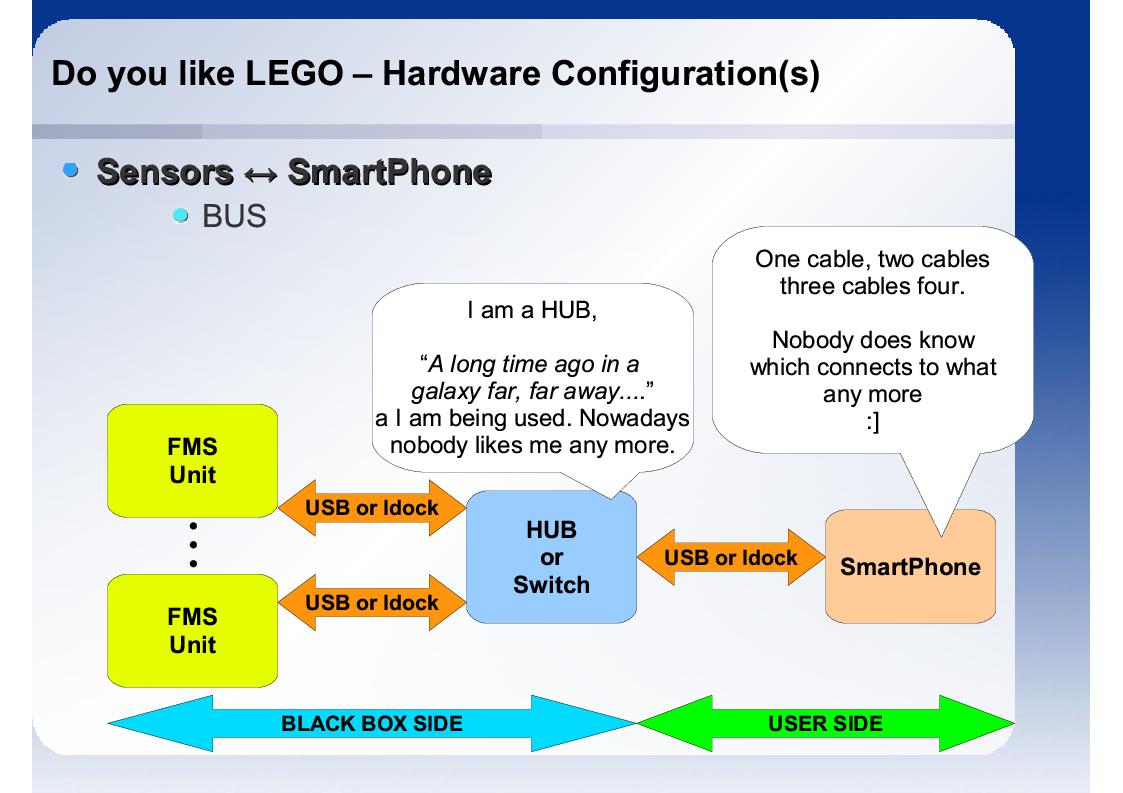
Rozwiązaniem poprzedniego problemu mógłby być HUB USB - co zminiejszałoby fizyczną ingerencję uzytkownika w MMS - podłączałby tylko jeden kabel. Takie rozwiązanie prowadzi jednak do zbyt dużej ilość okablowania po stronie projektowanego MMS - problemy ze skalowalnością.
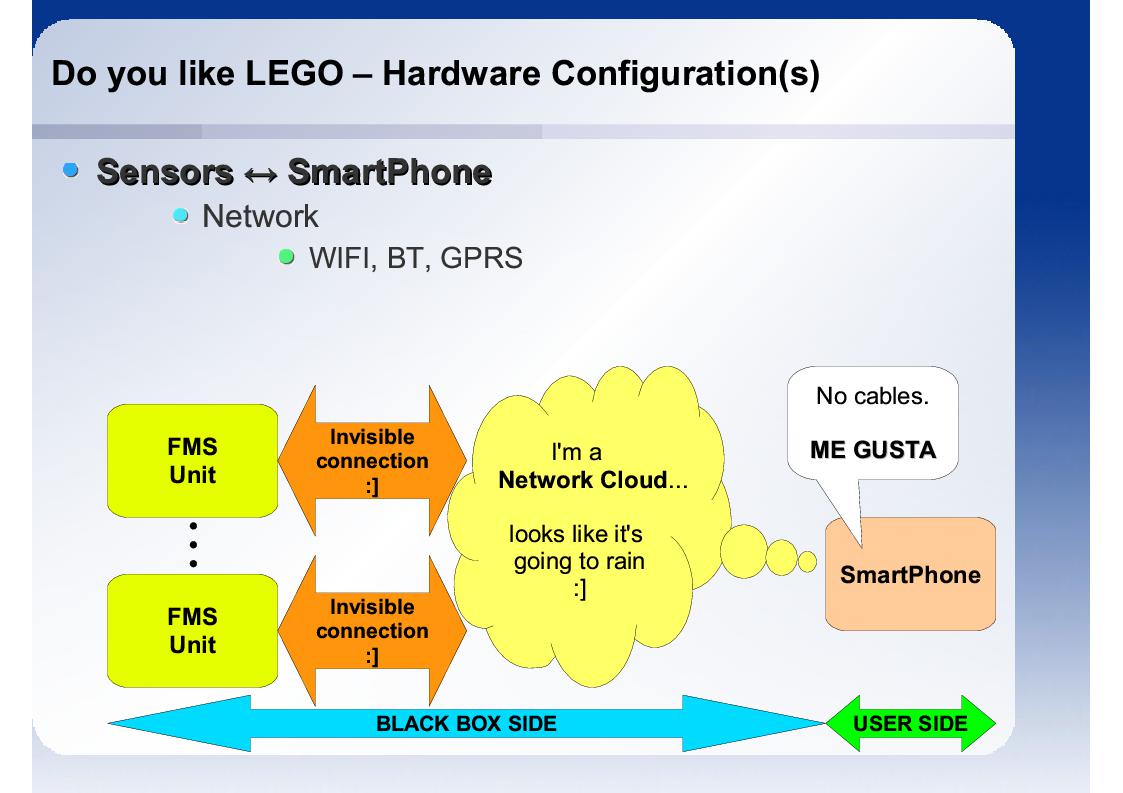
Jedynym pasujuącym dla użytkownika rozwiązaniem są interfesjy bezprzewodowe. Jednostki FMS również mogą być wyposażone w interfesjy bezprzewodowe co rozwiązywałoby dostatecznie problem ze skalowalnością.
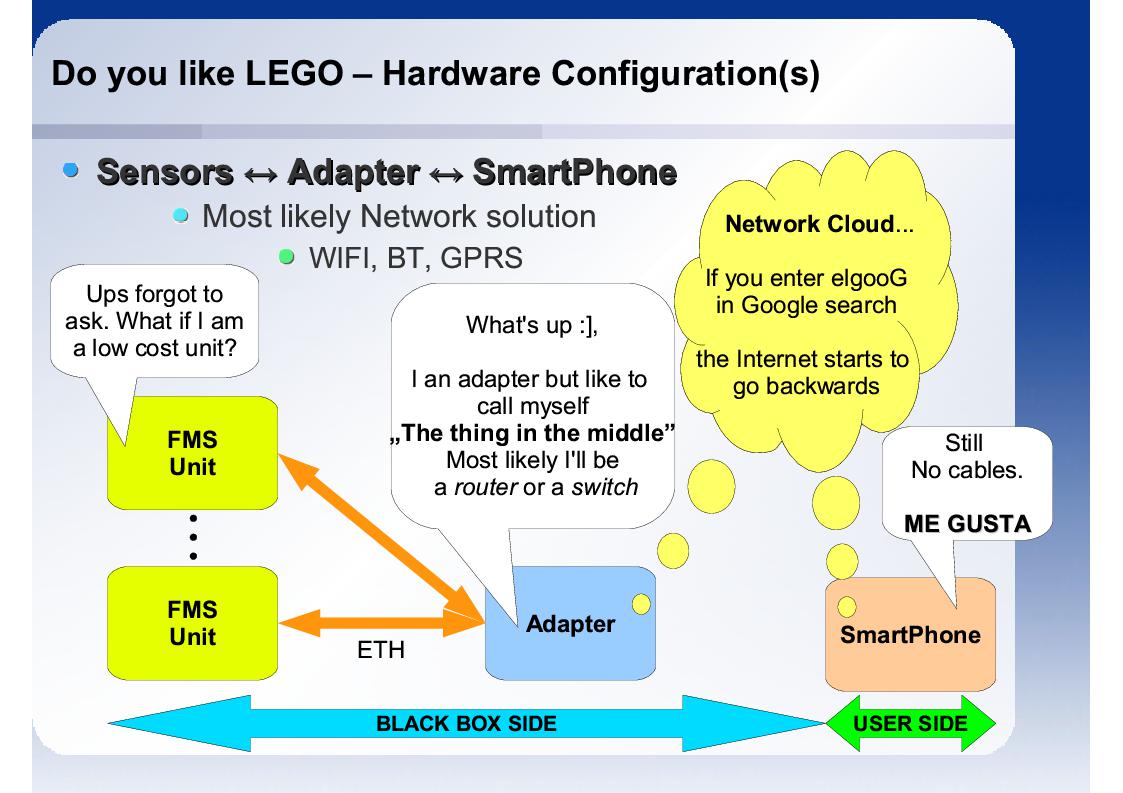
Niestety jednostki FMS typowo nie muszą być dużymi modułami. Mogą to być low-cost'owe rozwiązania nie zawierające fizycznych ani logicznych warstw RF - a np. tylko interfejs I2C do komunnikacji z czujnikiem znajdującym się na FMS. Rozwiązaniem mogłoby być tworzenie FMS opartych o interfejs Ethernet tak by dało się jednostki FMS podłączać do adaptorów RF - dostępnych jako "off-the-shelf". Niestety implementacja fizycznej i loginczej warstwy Ethernetu nie jest rozwiązaniem najtańszym.
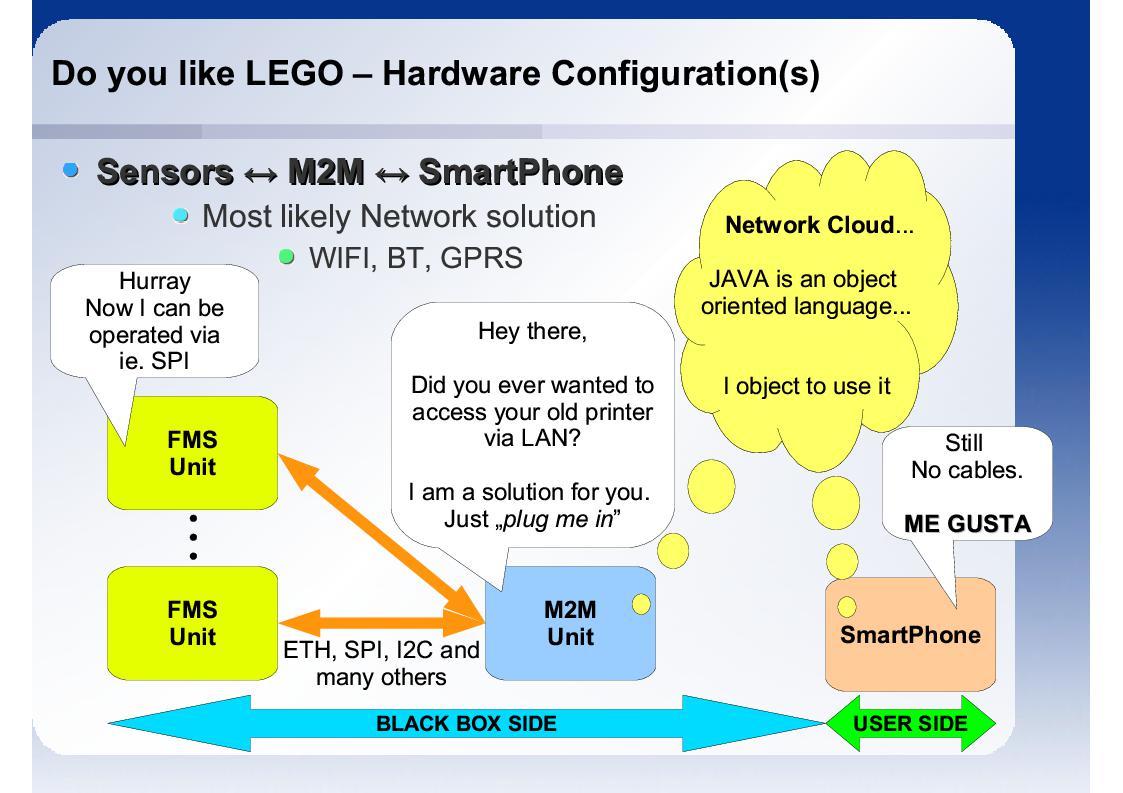
Dlatego najlepszym rozwiązaniem jest unwiersalna platforma M2M. Jednostki FMS są podłączone poprzez różne liczne [prsote i tanie w implemntacji] interfesjy tj. SPI, I2C, UART. Jednostka M2M w sposób transparentny łączy się z użytkownikiem wykorzystując interfesjy RF, stanowiać w ten sposób most.


Urządzenia stanowiące na dzisiejszy dzień MMS:
- SensorBox stanowiący jednostkę M2M: I2C<->GPRS, UART<->GPRS lub SPI<->GPRS,
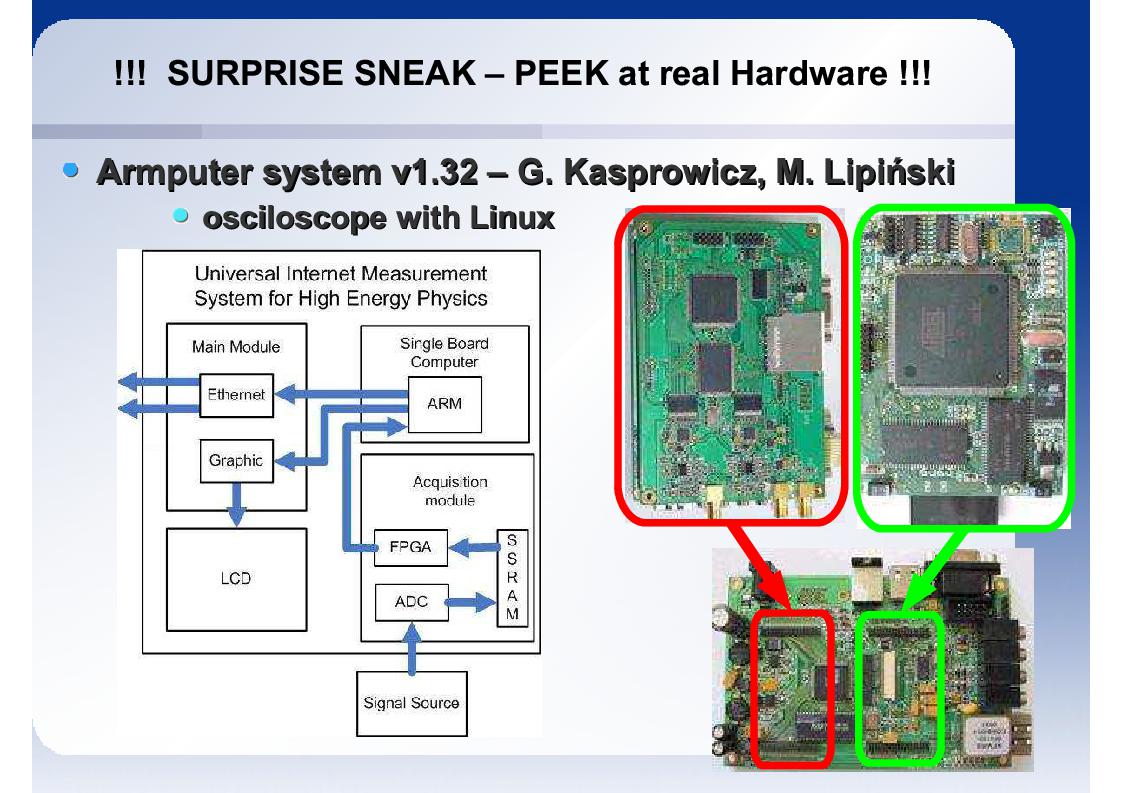
- Armputer V1 - stanowiący webowy oscyloskop,
- Armputer V2 - stanowiaćy jednostkę M2M z "prostych interfesjów" na tj. Bluetooth i GPRS,
- Zestaw uruchomineiowy Iphone wraz z MacBook.



Na potrzeby grantu tworzona jest nowa wersja Armputera zawierająca nowy interfesj WIFI oraz szybszy procesor, ethernet oraz pamięci. Wersja V3 będzie kompatybilna z nakładkami stworzonymi dla wersji V2


Postępy oraz plany zw. z trzecią wersją Armputera zostały zaprezentowane na kilku kolenych slajdach. W planach jest obecnie powtórne zweryfikowanie schematów gdyż pojawiała się na rynku opcja kupienia w pojedynczych sztukach układu warstwy fizycznej integrujących w jednym układzie scalonym BLE + WIFI.



| Attachment | Wielkość |
|---|---|
| MMS_v3.pdf | 1.21 MB |
Multi-Computing PC Card PC Card - Part 1

Prezentacja dotyczy:
- studneckiego możliwie nisko-budżetowego rozwiązania,
- karty wielofunkcyjnej PCI lub działającej samodzielnie,
- opartej o sprawdzone [starsze] układy scalone,
- oraz darmowe środowiska programistyczne do budowy software [C/C++] oraz firmware [HDL].
W ninniejszej części zostanie przedstawione rozumowanie oraz badanie rynku [na rok 2010] mające na celu wybranie najważniejszych elementów w projekcie tj: wstępnej koncepcji oraz wymagań projektowych, jak i kontrolera projektu planowanego jako jeden z układów spośród: FPGA, uP, uC albo DSP wraz z wymaganym dla niego środowiskiem programistycznym.

W prezentacji zostanie przedstawione:
- ogólna [wstępna] koncepcja rozwiązania,
- kryteria wyboru kontrolera,
- podsumowanie wraz krótkimi wnioskami przedstawionego badania rynkowego,
- krótkie przedstawienie wybranego kontrolera,
- wytyczenie działań na następny rok.
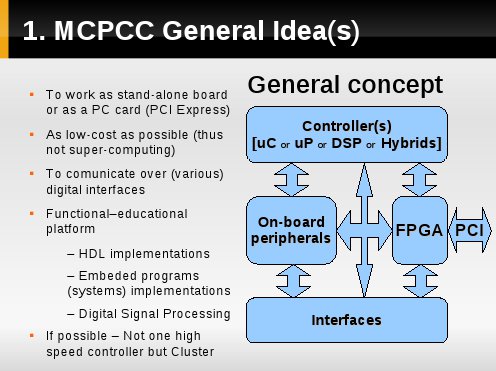
Ideą jest stworzenie:
- rozwiązania low-cost,
- mającego różne "popularne" i cyfrowe interfejsy,
- działająceo autonomicznie lub jako karta PCI,
- zawierającego połączenia łączące kontrolery w system wieloprocesorowy.
Karta w zamierzeniu ma stanowić:
- platformę edukacyjno-testową dla rozwoju technik wieloprocesorowych z użyciem FPGA,
- tani prototyp dla przetestowania nigdy dotąd nie testowanych połączeń uP-FPGA-Peryferia, polegających na przejęciu właściwej kontroli wszystkich możliwych peryferiów oraz interfejsów uP przez FPGA [o czym mowa jest dopiero w drugiej części prezentacji],
- możliwie efektywną [a ograniczoną ceną projektu] realizacją algorytmów przetważania video przy możliwie niskim zużyciu mocy.

Firmy oraz rodziny układów, które zostay uwzględnione do badań.
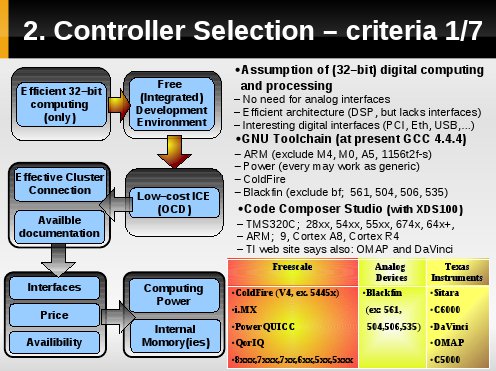
Układy z danych rodzinych zostały poddane tokowi eliminacji poprzez zadane kryterią jakimi są:
- wydajna architektura 32-bitowa [najlepsze byłyby DSP, które niestety najcześciej nie mają wbudowanych sprzętowych kontrolerów popularnych interfejsów],
- darmowe środowisko do budowy projektów.
Z badań wynika, iż istnieją dwie możliwe drogi progamistyczne zadanych kontrolerów:
- środowikso oparte o kompilatory GNU GCC [z ograniczeniami na nieobłsugiwane jak na 2010 architektury],
- środowisko firmy Texas Instruments, pełną licencję którego [ograniczoną do wybranych układów] otrzymuję się wraz wykupieniem programotra XDS100 wartego poniżej 100$.
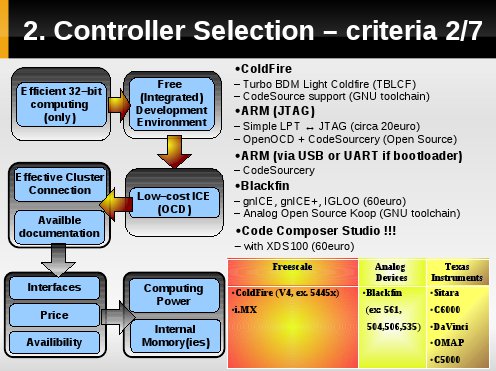
Płyta powinna być łatwo testowalna i programowalna, stąd kolejnym kryterium jest wybór takiego kontrolera dla którego istnieje tani programatror/debugger/emulator.
Z badań wynika, iż istnieją takie rozwiązania - niestety jednak:
- isnieje problem z dostępnością,
- należy stworzyć je samemu, gdzie dodatkwo nie ma gwarancji, że rozwiązanie zadziała.
Ewenenmentem są wybrane układy firmy Texas Instruemnts, gdzie programator [oparty o USB] XDS100 jest tani, a nawet jego schematy wraz z listą elementów są udostępnione publicznie.
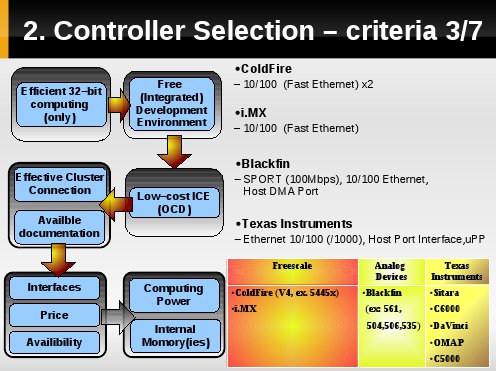
Kolejne kryterium stanowi by wybrany układ kontrolera umożliwiał połączenie dedykowane lub ułatwiające tworzenie systmu wieloporcesorowego.
Takie połączenie umożliwiją prezentowane układy/rodziny kontrolerów i są połączenia operte o interfejsy tj. Ethernet oraz dedykowane [jak Host Port Interface lub Universal Parallel Port].

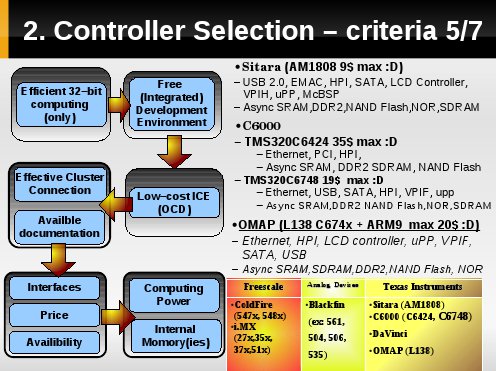
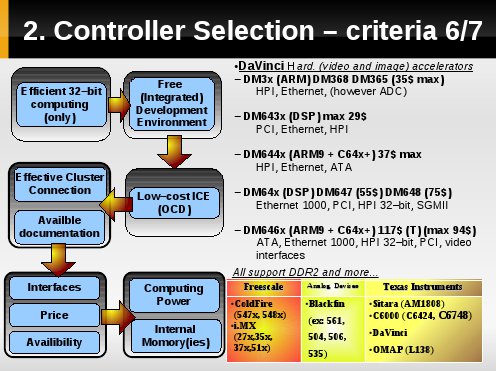
Kolejnym kryterium [5,6,7] są:
- zasoby,
- bogactwo obsługiwanych peryferiów/interfejsów,
- moc obliczeniowa,
względem ceny [peryferia+wydajność do ceny].
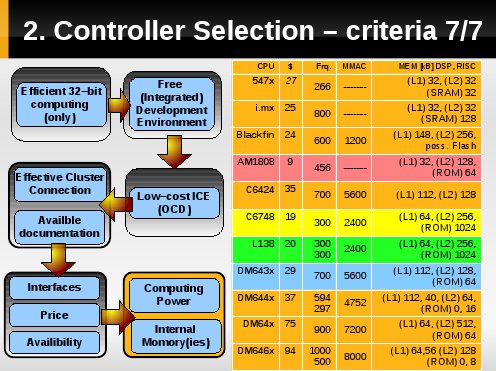
Lista podsumowywująca wyłania kilka możliwych rozwiązań. Kolrami łososiowym, żółtym, zielonym oraz niebieskim wyróżniono rozwiązania z możliwie największą wydajnością i bogactwem interfejsów względem ceny.
Przyjęte kryteria nie wyłoniły jednoznacznego "zwycięzcy" - wymienione rozwiązania plasują się identycznie cenowo jak i wydajnościowo. Za roziwązaniem z użyciem L138 opwiada się jednak doskonale stowrzona do niego dokumentacja wraz ze wsparciem w postaniu forum. Ponadto jest to jedyny na liście uP hybrydowy integrujący w jednym układzie scalonym rdzeń ARM oraz osobny rdzeń DSP połączonych wew. szyną, gdzie DSP działa jako coprocesor.

Z przeprowadzonych badań nad "tanimi" rozwiązanimi dla konotrolera można pokusić się o następujące stwierdzenia [na rok 2010]. Rozwiązanie z użyciem L138 plasuję się w połowie stawki... tam gdzie L138 traci niższą mocą obliczeniową tam nadrabia ciekawymi rozwiąaniami jak liczne "popularne" interfejsy czy dodatkowo zintergrowanym DSP na pokładzie układu scalonego.
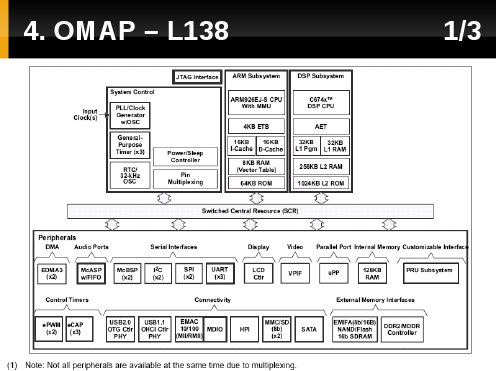
Tak wygląda w postaci blokowej architektura L138.
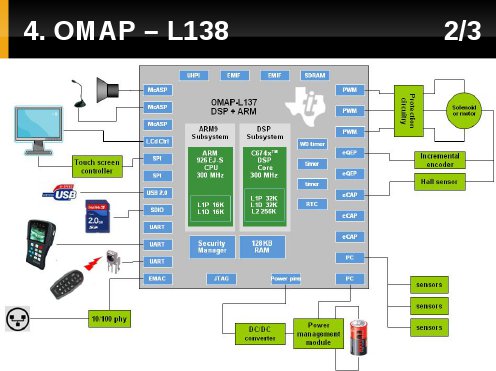
Tak wyglądają możliwości aplikacyjne z nim związane.

Na najbliższy rok planowane są:
- głębokie zapoznanie się z L138 wraz ze środowiskiem programistycznym,
- badania/studia literaturowe zw. z interfejsami tj. USB czy PCI w celach późniejszych ich optymlanego połącznia pod względem SI na płycie PCB, obsługi oraz implementacji kontrolerów danego interfejsu w FPGA,
- badania/studia literaturowe nad połączeniami wieloporocesorowymi/klastrowymi zarówno od strony sprzętrowej jak i programistycznej.

| Attachment | Wielkość |
|---|---|
| Multi-Computing Multi-Computing - Part 1.pdf | 3.72 MB |
Multi-Computing PC Card PC Card - Part 2

Prezentacja dotyczy:
- studneckiego możliwie nisko-budżetowego rozwiązania,
- karty wielofunkcyjnej PCI lub działającej samodzielnie,
- opartej o sprawdzone [starsze] układy scalone,
- oraz darmowe środowiska programistyczne do budowy software [C/C++] oraz firmware [HDL].
W ninniejszej części zostanie przedstawiony tok tworzenia architektury karty wraz z najważniejszymi połączeniami układów elektronicznych.

W prezentacji zostanie przedstawione:
- krótkie nawiązanie do części poprzedniej prezentacji,
- główne rozważania dzięki którym uzyskano architekturę,
- uwarunkowanie wyboru FPGA,
- przedstawienie właściwej architektury,
- wytyczenie działań na następny rok.
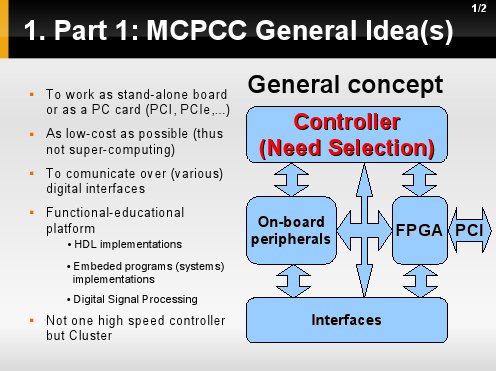
Generalnie MCPCC jest kartą samodzielną lub kartą PCI stanowiącą platformę dla:
- cyfrowego przertwarzania - głownie Video,
- systemów wbudowanych,
- systemów wieloprocesorowych,
- rozwojową HDL, C\C++, a w tym zw. z ESL gdzie FPGA stanowi koprocesor.
Na rysunku widzimy podstawową koncpecję, gdzie dostep do peryferiów oraz interfejsów płyty jest współdzielony przez kontroler wraz z układem FPGA - co ma umozliwać stworzenie połączeń typu sieciowego. Sprawdzone zostanie m.in. wydajność rozwiązania sprzętowego, gdzie FPGA stanowi koprocesor do działań nad strumieniem Video.
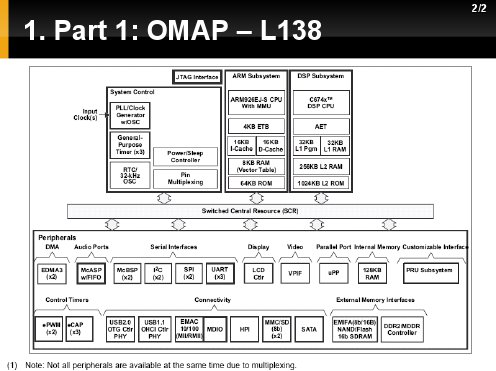
W poprzedniej prezentacji wybrany został hybrydowy kontroler uP+DSP L138. Jego zaletami poza wysokim współczynniem wydajności do ceny są zaimplementowane sprzętowo interfesjy na bazie których można stworzyć w pełni funkcjonalny "mini-komputer" tzw. "single board computer" lub kartę przetważania Video [jedno nie wyklucza drugiego]. Ponadto układ ten posiada dwa dedykowane interfesjsy do połączeń wieloprocesorowych:
- Host Port Interface [HPI]- dający mozliwość połączenia typu szeregowego wraz innym układem mającym taki interfejs,
- Universal Parallel Port [UPP] - dający mozliwość połączenia typu magistrali wraz z innymi układami niekoniecznie mającymi taki sam interfesj, gdyż protokół UPP jest kompatybilny z wieolma innymi np. z WishBone.

Architektura tworzona jest z myślą o jak najlepszym wykorzsytaniu interfesjów L138 i stworzenia optymalnych połączeń nieograniczjących funkcjonalności rozwiązania.
Głównymi przemyśleniami są: w jaki sposób połączyć dane interfesjy naszego uP tak aby stworzyć jak najwydajniejszy system wieloprocesorowy i zarazem zrobić to najmniejszymu kosztami. W przypadku gdy tworzymy system wiloprocesorowy [z zachowaniem umiaru w kosztach], to najmniejszym takim sytemem będzie system dwu-procesorowy [w zasadzie jest on cztero-procesorowy gdyż na pokładzie L138 znajduję się dodatkowo rdzeń DSP]. Jako, że nie jestesmy w stanie w pełni przewidzieć czy dana archotektura jest najlepsza, to warto pierw opracować prototyp tylko z dwoma uP by nie popaść w nic nieprzynoszące koszta i zweryfikować skalowalność rozwiązania.
Na obrazku widzimy, iż pierwszą ideą tworzącą naszą architekturę jest wykorzystanie 2 uP, gdzie wykorzystamy interfesj HPI jako połączenie bezpośrenide.
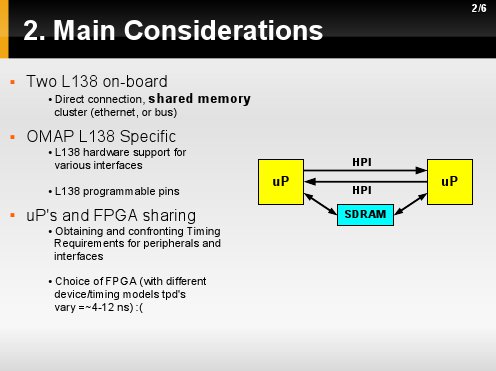
Mając już dwa uP możemy pomysleć nad innymi mozliwościami połączeń takimi jak współdzielona pamięć. Takie połączenie może stanowić kolejny mechanizm w wymianie informacji pomiędzy procesorami w systemi wieloporcesorowym.
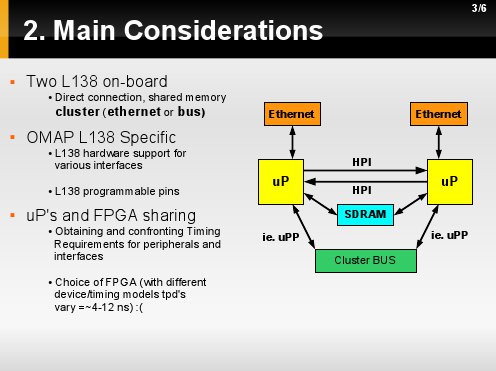
Kolejnymi pomysłami jest stowrzenie magistrali oraz możliwości połączenia przez Ethernet.
Nasza architektura tworzona jest tak by wykorzystać wszystkie mozliwości jakie daje L138 do stworzenia systemu wieloprocesorowego tak aby projektant oprogramowania mógł wykorzystać najwydajnieszy sposób połacznia dla zadanego [swojego] algorytmu/zadania.
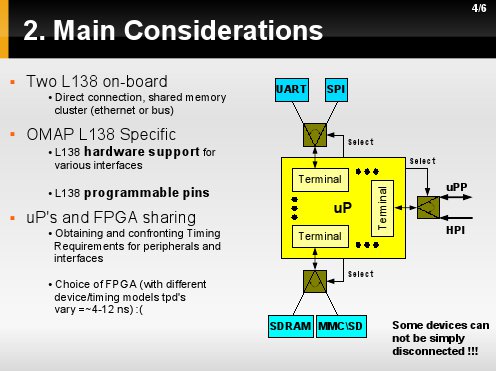
L138 posida sprzętowe wsparcie dla wielu interfejsów ciekawych z punktu widzenia platformy rozwojowej. Niestety nie są one dostepne wszystkie naraz - są one komutowane i mogą być komutowane podczas działania online. Niestety niktóre interfejsy [w zalezności do czego i jak są podłączone] nie mogą być współdzielone np. UART z I2C. Nie mogą przeto być komutowane a muszą być wybrane na stałe. Ponadto na róznych interfejsach które nawet dałoby się podłączyć równolegle podczas komutacji może dojć do nieprzewidywanych zachowań.
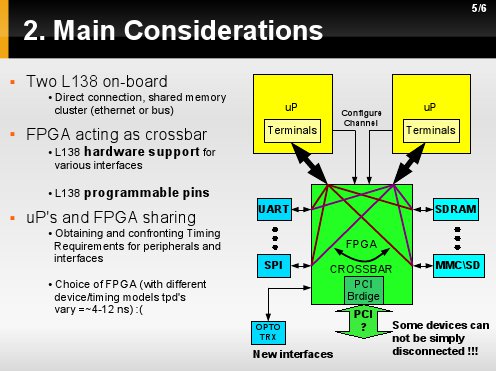
Stąd pomysł na podłączenie jak największej ilośći pinów uP do FPGA, które w prostym ujęciu stanowi powielacz pinów, a wew. FPGA może zachodzić "inteligętna" komutacja.
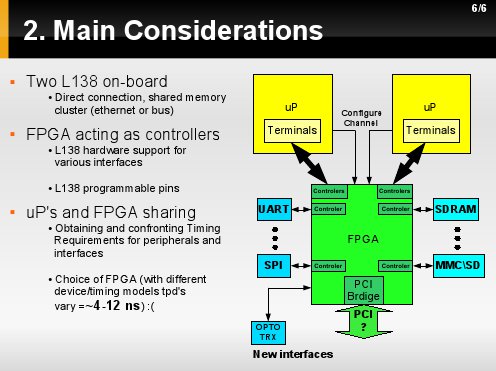
Lub nawet zamiast tylko komutacji przejęcie sterowania na dowolnym interfesjem poprzez stowrzenie kontrolerów/arbitrów - otrzymujących sterowanie/dane z uP lub pełniące funkcję DMA.

By propopnowane rozwiązanie uzykało pełny potencjał, tj. każdy interfesj L138 mógłbyć fizycznie dostepny, należałoby użyć FPGA o ponad 740 funkcjonalnych pinach. Takie FPGA są poza zakresem obsługiwanych w darmowych wersjach środowisk do tworzenia firmware dla FPGA [na rok 2011]. By sprostac wymaganiowi na niskie koszta zostało ustalone, iż nie wszystkie możliwości L138 zostaną zaimplementowane. Prowadzi to do zrezygnowania z wielu połączeń, które miały pierwotnie przechodzić przez FPGA.

Do projektu zostanie wykorzystany największy pod względem ilości dostęnych IO oraz jednocześnie wspierany przez darmowe wersje oprgoramaowania [na rok 2011] do tworzenia firmware - Cyclone II. Główe parametry widoczne są na rysunku.
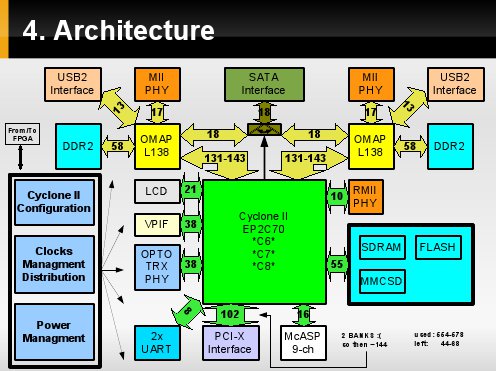
Tak prezentuję się architektura. Przez FPGA zostaną przepuszczone [współdzielone] interfejsy:
- VideoIn,
- VideOut - LCD,
- Audio,
- pamięć FLASH [bootowanie L138 poprzez FPGA],
- UPP oraz HPI,
- interfesjs do zew. PHY [SerDes'a] optycznej transmisji danych.
Dedykowanymi dla danego uP będzie połączenie z:
- PHY ethernetowym interfesjem MII,
- DDR2,
- USB,
- komutowanym kontrolerem SATA podłączonym do zew. dysku.

Po opracowaniu architektury [co wymagało zweryfikowania fubkcjonalności L138 wraz z wybranym FPGA], można przejść do opracowywania PCB oraz fimrware na FPGA. Jako, że wiele interfejsów jest "przepuszczona" przez FPGA, a interfesjy te mają wymagania/rygory czasowe w których transmisja musi się mieścić, to należy pierw opracować firmware by uzyskać opóxnienia czasowe zw. z architekturą wew. FPGA. Opóźnienia te należy wziąść pod uwagę razem z opóźnieniami ścieżek zasymulowanych w oprogramowaniu tj. HyperLynx lub Altium Desinger.

| Attachment | Wielkość |
|---|---|
| Multi-Computing PC Card PC Card - Part 2.pdf | 178.51 KB |